
The Architecture Secrets Behind Apps That Scale to Millions
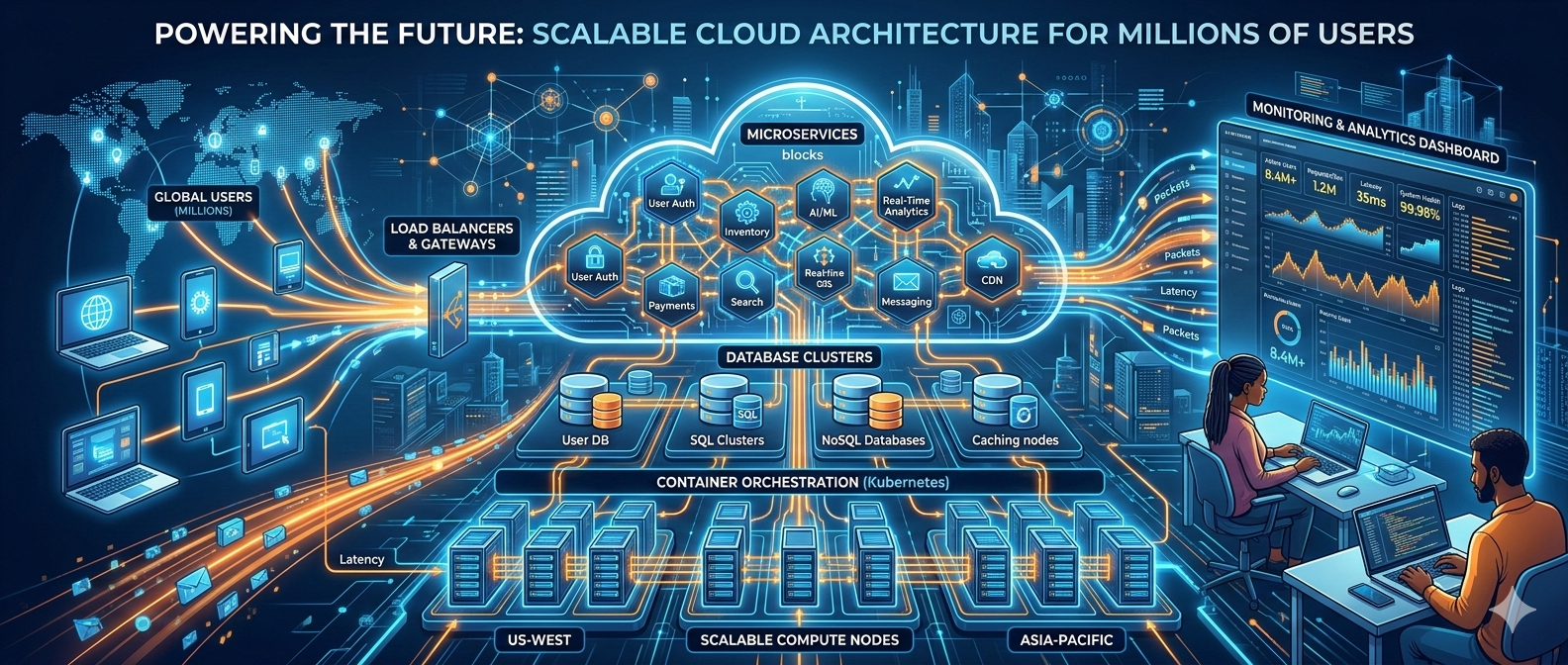
Applications that support millions of users require a strong and scalable architecture to maintain performance, reliability, and fast response times. Instead of relying on a single large system, modern apps often use microservices architecture, where different parts of the application run as independent services. This allows developers to scale only the components that need more resources.
Cloud infrastructure also plays a key role by enabling apps to automatically scale when traffic increases. Techniques like load balancing, caching, and database scaling methods such as sharding and replication help distribute workloads and manage large volumes of data efficiently.
In addition, practices like DevOps, continuous deployment, and real-time monitoring ensure that systems stay stable as they grow. By combining these technologies and strategies, companies can build applications capable of handling millions of users while delivering a smooth and reliable user experience.
The Architecture Secrets Behind Apps That Scale to Millions
Building an app that handles millions of users isn't magic. It's deliberate architecture, careful trade-offs, and a lot of small decisions that add up. Over the years I've seen teams focus on shiny frameworks and micro-optimizations while ignoring the fundamentals. The result? An app that creaks and fails the moment traffic spikes.
Agami Technologies is a forward-thinking technology company that helps businesses build scalable, high-performance digital solutions. From custom software development to cloud and AI-powered systems, the team focuses on creating reliable applications designed to grow with your business and support millions of users efficiently.
In this post I’ll walk through the architecture patterns, infrastructure choices, and operational practices that actually work for high-traffic application architecture. I’ll share common pitfalls, concrete examples, and practical checks you can run on your own systems. If you're building something that needs to scale—whether you're a startup founder, CTO, or lead developer—this is for you.
Why architecture matters more than the latest tech
People often ask whether to pick Serverless, Kubernetes, or the “best” database. Truth is: the tech matters less than how you structure boundaries, responsibilities, and failure domains.
I've noticed teams that pick a stack for buzzwords and then try to retrofit scalability. That rarely works. Instead, start with a clear separation of concerns: which parts need to scale independently, which must stay strongly consistent, and where eventual consistency is acceptable.
Put simply: architecture is about trade-offs. Plan them consciously.
Core principles of scalable app architecture
- Modularity and isolation. Independent services mean independent scaling, deployments, and failures.
- Statelessness at the edge. If your web/application nodes are stateless, you can add/remove instances quickly without sticky sessions.
- Design for failure. Expect components to fail and degrade gracefully. Use retries, timeouts, and circuit breakers.
- Automate everything. Manual ops don’t scale. Infrastructure as code, CI/CD, and automated testing are table stakes.
- Observe continuously. You can’t fix what you don’t measure. Metrics, logs, and tracing are crucial.
- Make data-driven decisions. Capacity planning and cost optimization need real usage data, not guesses.
Those principles sound obvious, but they’re hard to apply consistently. They influence every design choice from API contracts to database topology.
Microservices: the right tool for the right job
Microservices architecture gets a lot of blame and praise. In my experience, it’s powerful when you use it for the right reasons: to isolate teams, scale components independently, and manage complexity. Problems crop up when teams split services prematurely or don’t invest in cross-service contracts and testing.
Consider the trade-offs:
- Pros: isolation, independent deployments, targeted scaling, and clear ownership.
- Cons: operational complexity, network latency, and the need for robust observability and service discovery.
For startups, a hybrid approach often works best: start with a well-structured monolith (modular codebase, clear boundaries) and extract services as you identify real scalability or organizational bottlenecks. This is the “strangler fig” approach in practice.
Event-driven and asynchronous patterns
High-traffic systems benefit from async processing. Moving work off the critical request path reduces latency and increases throughput.
Patterns I use regularly:
- Message queues (SQS, RabbitMQ) for reliable asynchronous tasks.
- Streaming platforms (Kafka, Pulsar) for event sourcing, audit logs, and fan-out processing.
- Event-driven microservices that react to events rather than blocking on synchronous RPC.
Key things to watch: idempotency, ordering guarantees, schema evolution, and dead-letter queues. I've seen teams forget idempotency and get duplicate side effects during retries—costly and painful to debug.
Cloud infrastructure, containers, and orchestration
Cloud providers offer the primitives you need: regions, availability zones, load balancers, and managed services. But the magic is in how you organize those primitives.
Containers + orchestration (Kubernetes, ECS) give you portability and predictable deployments. They also demand good operational practices: health checks, resource limits, rolling updates, and readiness probes.
Serverless (Lambda, Cloud Functions) can be an easy path to scale for stateless workloads, but watch out for cold starts, execution time limits, and vendor lock-in. I recommend serverless for glue logic, event processors, or infrequent but bursty jobs—not for everything.
Load balancing and traffic management
Load balancing is more than round-robin. At scale you need global traffic management, intelligent routing, and rate limiting.
- Edge and CDN first: put assets and cacheable API responses on a CDN. It reduces origin load and shortens latency.
- Global load balancers (Route 53/Cloud DNS + GSLB) route users to the nearest region and support failover.
- Layer 7 gateways (API Gateway, NGINX, Envoy) provide request-level routing, authentication, and rate limiting.
During a major flash sale or PR-driven traffic spike, a lot of issues are traffic-management problems: bad cache behavior, sticky sessions, or a single bottleneck service. Build throttling and graceful degradation into your APIs.
Scaling the data layer: replication, sharding, and partitioning
Data is often the hardest part to scale. The right strategy depends on read/write patterns, consistency needs, and operational appetite.
Common strategies:
- Read replicas (RDBMS replication) to scale read-heavy workloads.
- Sharding (horizontal partitioning) to split write load across nodes. Shard by user ID, tenant ID, or geography—pick a shard key that minimizes cross-shard operations.
- NoSQL stores (Cassandra, DynamoDB, MongoDB) for high write throughput and flexible schemas. They trade relational features for scale and availability.
A few practical tips:
- Plan for hotspots. A poor shard key causes one node to get all the traffic.
- Avoid cross-shard transactions when possible. They greatly complicate the architecture.
- Use materialized views or denormalized tables for frequent join-heavy access patterns.
I've worked on apps that started with a single Postgres instance, then added read replicas, and finally sharded when writes became the bottleneck. Each step added complexity, so we only did them when metrics justified the change.
Caching: strategy and pitfalls
Caching is a multiplier. Cache right and you reduce backend load dramatically. Cache wrong and you face stale data, inconsistent views, and cache stampedes.
Patterns that work:
- CDN + edge caching for static assets and cacheable API responses (e.g., user profiles that rarely change).
- Application-level caches (Redis, Memcached) in cache-aside mode for expensive read paths.
- Write-through / write-behind when you need stronger cache consistency guarantees.
Pitfalls to avoid:
- Cache stampede: protect hot keys with locking or exponential backoff.
- Unbounded cache growth: set eviction policies and TTLs.
- Opaque cache invalidation: design clear invalidation rules and test them.
APIs, rate limiting, and graceful degradation
Your APIs are the surface area of your product. Protect them.
- Document and version APIs. Backward-incompatible changes without coordination break clients.
- Use rate limits and quotas per user/tenant to prevent noisy neighbors.
- Implement bulkhead patterns so a failing downstream service doesn’t take down unrelated flows.
- Provide graceful degradation: feature flags, partial responses, and cached fallbacks keep the user experience acceptable under stress.
In practice I’ve seen teams restart entire services because a single client flooded them. A combination of quotas, per-API rate limits, and circuit breakers usually prevents that.

Asynchronous messaging: Kafka, SQS, and patterns that scale
Message brokers are the glue for many scalable systems. They decouple producers from consumers and smooth traffic spikes.
Pick the right tool for the job:
- Kafka for high-throughput streaming, event sourcing, and long retention windows.
- SQS / Pub/Sub for simple, durable queues where ordering isn’t strict.
- RabbitMQ for complex routing and messaging patterns with lower throughput than Kafka.
Operational tips:
- Design consumers to be idempotent.
- Use consumer groups to scale processing horizontally.
- Monitor lag closely—growing lag is a clear sign consumers can't keep up.
- Use dead-letter queues and explicit retries to handle poison messages.
DevOps and CI/CD: deploy reliably, roll back fast
Continuous integration and deployment are how you move from a working architecture to a resilient one. If your deployments are risky, you'll never iterate safely at scale.
Essential elements:
- Automated tests (unit, integration, and load tests) in CI pipelines.
- Immutable artifacts and versioned releases.
- Blue/green or canary deployments to reduce blast radius.
- Automated rollbacks when health checks fail.
- Infrastructure as code (Terraform, CloudFormation) and a git-driven workflow for infra changes.
A note from my experience: the first real stress test for a pipeline usually reveals assumptions about stateful migrations and operational runbooks. Run the tests before the traffic hits you.
Build Scalable Applications with Agami Technologies
Designing applications that can support millions of users requires the right technical expertise and a strong development strategy. Agami Technologies specializes in building scalable digital products that combine modern architecture, cloud infrastructure, and efficient system design. Their custom software development help businesses create reliable applications that grow with user demand while maintaining high performance and security.
Whether you are launching a startup product or upgrading an existing platform, working with experienced developers ensures your system is prepared to handle future growth without performance issues.
Monitoring, observability, and SLOs
Observability is often the difference between surviving and failing an outage. Metrics tell you what happened; traces tell you why.
- Collect metrics at service, endpoint, and infrastructure levels. Use Prometheus, StatsD, or cloud metrics.
- Aggregate logs centrally. Structured logs help with filtering and correlation.
- Instrument distributed tracing using OpenTelemetry, Jaeger, or Zipkin to follow requests across services.
- Define SLIs and SLOs (latency, error rate, availability). Let them drive prioritization.
When I onboard new teams, I ask: what are your three most important metrics? If they can't answer quickly, observability needs work.
Security, compliance, and data governance
Scaling responsibly means keeping users' data safe and complying with regulations. Security decisions should be part of your architecture, not an afterthought.
- Encrypt data in transit and at rest.
- Centralize secrets management (Vault, cloud KMS).
- Use least privilege for service accounts.
- Audit access and automate compliance checks where possible.
For multi-tenant apps, isolate tenant data to prevent leakage and make audits simpler. I've seen teams try to bolt security on late in the process—don't be that team.
Cost management and capacity planning
Scaling is not free. Without cost control, high traffic becomes an unsustainable bill.
Practical cost levers:
- Autoscaling to match demand instead of over-provisioning.
- Right-size instances and use reserved/spot instances where appropriate.
- Cache aggressively to reduce backend compute and DB costs.
- Use serverless where it reduces operational overhead and cost for low-to-medium sustained loads.
Capacity planning is more than predicting peak traffic. It’s about understanding bottlenecks, identifying single points of failure, and having cost-aware fallbacks (e.g., serving lower-resolution images under heavy load).
Organization and process: people scale systems
Architecture is only as good as the people operating it. Team structure and processes matter hugely.
- Give teams end-to-end ownership for services: code, infra, and incidents.
- Establish clear API contracts and versioning policies.
- Maintain runbooks and postmortems for incidents. Share learnings across teams.
- Run chaos experiments (e.g., controlled failures) to test resilience assumptions.
I've coached teams that improved mean time to recovery (MTTR) dramatically simply by improving runbooks and practicing playbooks under load.
Common mistakes and how to avoid them
- Premature microservices: Start with a modular monolith and only split when you hit real limits.
- No observability: Deploy without metrics and you’re flying blind.
- Tight coupling to a single region: Multi-region planning can be done incrementally—don't ignore it until it's too late.
- Bad shard keys: Choose shard keys based on access patterns, not convenience.
- No circuit breakers or timeouts: Synchronous calls that hang can cascade into full-blown outages.
- Overuse of synchronous flows: Put non-critical work onto queues and background workers.
- Ignoring cost implications: Scale decisions should balance performance and budget.
Avoiding these is mostly about discipline: instrument, measure, and prioritize fixes that buy you the most reliability per dollar.
Realistic architecture examples
Below are concise examples I’ve used when advising startups. They show typical trade-offs and why they work.
Consumer social app (millions of daily active users)
- API layer: global CDN at edge, regional API gateways with rate limiting.
- Service layer: microservices split by domain (feed, social graph, media), deployed in multiple regions via Kubernetes.
- Data: user metadata in relational DB with read replicas; timelines stored in a high-throughput NoSQL store (Cassandra) and materialized feeds in Redis for fast reads.
- Messaging: Kafka for event streams (activity, notifications). Consumers write to offline analytics and personalization models.
- Media: object storage (S3) + CDN, transcoding pipeline in serverless or batch workers.
Why it works: separation of read-heavy timeline reads from write-heavy social graph updates, and event-driven pipelines for personalization at scale.
E-commerce during sales peaks
- API: edge cache for product pages, API gateway with strict rate limits and throttling during checkout flows.
- Checkout: small, isolated service with its own DB to minimize blast radius and ensure ACID for transactions.
- Inventory: eventual consistency with optimistic locking and inventory reservations via a distributed lock or reservation queue.
- Scaling: autoscaling workers for order processing and a transactional service for payments with circuit breakers.
Why it works: isolating checkout guarantees consistent purchases, while caching and pre-warming limit load on product catalog services during spikes.
Checklist: Is your app ready to scale?
Use this quick checklist to evaluate readiness. If you answer "no" to any, that’s an action item.
- Can you add/remove application instances without downtime?
- Do you have end-to-end tracing and metrics for user-facing flows?
- Are your critical services stateless or have clear sticky session strategies?
- Is there a documented plan for scaling the database beyond read replicas?
- Do you have rate limits and per-tenant quotas?
- Are deployments automated with safe rollbacks and canary support?
- Is there a disaster recovery plan and tested backups for critical data?
- Are teams organized around services and empowered to handle incidents?
Small, high-impact changes you can make this month
If you're short on engineering time, these changes often give the best ROI:
- Instrument critical endpoints with latency and error metrics.
- Add or tighten timeouts and retries with exponential backoff.
- Introduce a CDN for static assets and cacheable responses.
- Set up read replicas for your database if reads dominate.
- Implement circuit breakers around third-party calls.
These moves typically reduce mean latency, cut backend load, and make issues easier to debug.
When to bring in external expertise
Scaling to millions often requires specialized knowledge and operational experience. Bring someone in when:
- Your team spends most of its time fighting incidents.
- You're facing architectural changes like sharding or multi-region deployment for the first time.
- Cost and performance are out of balance and you don’t know which bottlenecks to tackle first.
At Agami Technologies we've helped teams perform architecture audits, design sharding strategies, and implement robust CI/CD pipelines. Bringing in experts can shorten your learning curve and reduce costly mistakes.
Parting advice: trade-offs, not silver bullets
There’s no single blueprint that fits every app. Scaling is a continuous process of measurement, trade-offs, and iteration. You’ll need to balance consistency against availability, feature velocity against operational complexity, and performance against cost.
Keep the focus on a few key objectives: reduce blast radius, observe everything, and automate to eliminate manual toil. Make small, reversible changes and measure their impact. That’s how you get from a functional app to one that scales reliably to millions.
Helpful Links & Next Steps
- Agami Technologies — Company
- Agami Technologies Blog
- Book a session: Build a Scalable App With Our Experts
If you want help assessing your architecture, shaping a roadmap, or building a proof-of-concept that scales, get in touch. We’ve done the hard work and we’ll help you avoid the usual pitfalls.