
Cloud Application Development: Building Faster, Smarter Digital Apps
Cloud-native application development is presented as the operating model for modern software teams: deliberate architectural, tooling, and organizational choices determine speed, cost, and resilience. The blog explains core principles of microservices and modularity, infrastructure as code, continuous delivery, observability, and automated policy, and gives practical guidance on splitting monoliths, choosing containers versus serverless, picking cloud providers, managing costs, security, data, testing, and migrations. It offers a staged roadmap, short experiments to try, common mistakes to avoid, and metrics to measure success. The purpose is to help product and engineering leaders adopt cloud-native practices intentionally and know when to bring in expert partners.
Cloud-native application development is not a trend. At Agami Technologies, we see it as the operating system for modern software teams. If you are building a SaaS product, scaling a platform, or planning a major migration, the choices you make now shape how fast you can move later and how resilient your business becomes.
I’ve worked with founders and product leaders who think of cloud projects as purely technical. In my experience, the bigger win is organizational. You can build fast and cheap, or you can build slow and durable. The sweet spot is fast and durable, and cloud-native choices get you there when you do them intentionally.
This post walks through practical signals, patterns, and pitfalls for cloud application development. You’ll find clear explanations of architectures, tooling, migration paths, and how to set teams up for long term leverage. I’ll call out common mistakes I’ve seen and share small examples you can try right away.
Why Cloud-Native Matters
Cloud-native application development changes how you think about shipping work. Instead of buying servers and guessing capacity, you rely on elastic infrastructure and managed services. That means you can:
- Launch features faster by avoiding operations work.
- Scale users without rewriting your stack at the last minute.
- Optimize costs with pay for use pricing.
- Ship experiments and roll them back safely.
Think about the last time an unexpected spike hit production. Did you scramble to add machines? Or did your system absorb the load? The second case is a cloud-native win.
Cloud-native also unlocks managed services. Databases, queues, analytics, identity, and more are offered as services. You spend engineering time on product and behavior, not on running infrastructure.
Core Principles of Cloud Application Development
At its heart, cloud-native development follows a few simple principles. These guide architecture, team structure, and process.
- Microservices and modularity. Break applications into independently deployable components. That allows teams to ship without stepping on each other.
- Infrastructure as code. Declare your infrastructure so environments are reproducible and reviewable.
- Continuous delivery. Automate building, testing, and deploying often.
- Observability. Collect logs, metrics, and traces so you can understand behavior quickly.
- Automation and policy. Automate security checks, compliance scanning, and policy enforcement so manual gating disappears.
These principles form the baseline for scalable cloud applications. None of them is magic. Each one requires tradeoffs and discipline. If you try to adopt everything at once, teams can get overwhelmed. Start with one principle and expand.

Microservices vs Monolith: When to Split
Microservices are popular, but they are not always the right first step. A single well-structured monolith can be easier to reason about early on. The question should be: how do we enable speed while keeping code manageable?
I’ve seen startups break a codebase into microservices too early. The result was slow feature delivery, duplicated effort, and coordination overhead. If your team is small, keep things simple. When tech boundaries start to slow development, that is the sign to consider splitting.
Consider these signs you’re ready to move to microservices:
- Teams are blocked from each other more than 50 percent of the time.
- Different parts of the product require different scaling patterns.
- Failure in one area must be isolated from others for safety.
Start by extracting vertical slices. Pick a small, independent function and extract it. Keep interfaces stable and limit cross-service transactions. Simple examples often work best. Move slowly and measure the impact on delivery speed.
Serverless, Containers, and Managed Services
Picking compute is one of the first technical decisions. Containers on Kubernetes give you control and portability. Serverless functions let you focus on code and ignore servers. Both have pros and cons.
Use containers if you need consistent runtime, custom binaries, or long-lived processes. Choose serverless if your workload is spiky, event driven, or you want minimal ops burden. In many systems, you will use both.
Managed services are a huge time saver. Instead of running Redis or Kafka yourself, you can pick managed equivalents. That reduces operational load and often improves reliability. But it can increase vendor lock in. Be deliberate about the tradeoff and document the escape hatch.
Cloud Providers: AWS, Azure, and More
Each cloud provider has its own strengths. AWS offers the broadest range of services and a large ecosystem of tools and integrations. Azure integrates closely with Microsoft enterprise environments and is often preferred for organizations running Windows-based workloads. Google Cloud Platform stands out for its advanced data analytics and machine learning capabilities. These platforms also provide the scalable infrastructure needed by companies offering crypto wallet app development services, enabling secure deployment, high availability, and reliable performance for blockchain applications.
When choosing a provider, focus on two things. First, which provider offers the managed services you will actually use? Second, which one does your team have experience with? Migration costs and productivity are both real expenses.
For example, if you plan to use serverless heavily, AWS Lambda has an extensive ecosystem and proven patterns. If you are building an enterprise SaaS that integrates with Microsoft 365, Azure might reduce friction. Either way, plan for multi cloud later only if you have a good reason. Multi cloud can add complexity without clear near term benefits.
DevOps, CI/CD, and Developer Experience
Developer experience matters more than most leaders realize. The easier it is to get a change from local to production, the more experiments teams will run. Continuous integration and continuous delivery let you ship often and safely. If you’re evaluating structured Cloud and DevOps implementation, explore our Cloud DevOps services
Here is a basic pipeline I recommend for almost every team:
- Developer pushes a branch and opens a pull request.
- Automated tests run: unit, integration, and linting.
- A preview environment spins up for manual verification.
- After approval, the change deploys to staging and then to production using automated rollout strategies.
- Monitoring and alerts confirm success. If something fails, automated rollback triggers.
Feature flags are another essential tool. They let you decouple deployment from release. Roll a change out gradually, test in production, and kill the flag if something goes sideways. Small teams can move faster and safer when they use flags from day one.
Observability and Monitoring
Observability is not just about charts. It is about enabling quick answers to the question of why. Logs, metrics, and distributed tracing are complementary. Use them together.
Set up baseline SLOs early. Define what healthy looks like and an instrument for it. You do not need complex systems to start. Track latency and error rates for key user journeys. Add capacity and cost metrics later.
One common mistake is looking only at system metrics. Those tell you if the servers are healthy, but not whether customers are having a poor experience. Map your metrics to user journeys. If checkout is slow, track the user facing timing. That connects ops with product decisions.
Security and Compliance
Security should be part of the design from day one. If you bolt it on later, it slows everyone down. Use identity first. Manage secrets centrally. Enforce least privilege with role based access control. Rotate keys automatically.
For regulated industries, bring compliance into the early conversations. Consider encryption at rest and in transit. Keep an audit trail. Many cloud providers offer managed services that simplify compliance, but you must understand shared responsibility models. That means some responsibilities remain with you.
Good practices to adopt now:
- Use managed identity providers and single sign on.
- Store secrets in a managed secrets manager, not in code or environment files.
- Run automated security scans in your CI pipeline.
- Restrict access to production resources and review permissions regularly.
Data Patterns and State Management
Stateless services are easier to scale. Keep state in managed databases or dedicated caches. Avoid ad hoc state within application instances.
Pick the right data store for the job. Use relational databases for transactional consistency and document stores for flexible schemas. Event streams are a good fit when you need to decouple services and replay events for analytics.
One trap I see is treating the database as the integration layer. That creates coupling and makes services fragile. If two services share a single database schema, you lose the benefits of independent deployability. Use APIs or event streams instead of direct reads and writes across service boundaries.
Migration Strategies: Lift and Shift vs Replatforming
Most migrations fall into one of three options. Each has a different cost and payoff.
- Lift and shift. Move existing servers to the cloud with a few changes. Fast to execute but misses cloud benefits.
- Replatform. Make limited changes to take advantage of managed services. Lower risk and good cost benefit.
- Refactor. Rewrite parts of the application to be cloud-native. Highest payoff and highest effort.
Choose the path based on business priorities. If you need to reduce data center costs quickly, lift and shift can be pragmatic. If you want to become cloud-native, plan a staged refactor focusing on the most valuable components first.
Common mistake: betting on a full refactor without a timeline or measurable milestones. Refactors cost time, and teams will lose momentum without small wins. Break work into increments and measure performance, cost, and delivery speed.
Cost Management and Optimization
Cloud gives you flexibility, but bad configuration leads to waste. In my experience, cost surprises often come from three places: orphaned resources, oversized instances, and unoptimized managed services.
Start with a cost baseline and use the Mega Calculator to estimate expenses accurately. Tag resources by team and product, run weekly cost reviews, and set budgets with alerts. Use autoscaling and right-sizing tools, and reserve capacity when you can predict sustained usage.
Remember that developer productivity is part of the cost. Paying for a managed service that saves weeks of engineering time can be cheaper in the long run. Don’t optimize cost at the expense of velocity unless you have to.
Microservices Communication and Data Consistency
When services are separated, they need to communicate. Synchronous calls are straightforward but create tight coupling. Asynchronous patterns reduce coupling but add complexity.
Use event driven architecture when you need loose coupling and replayability. Use sagas or compensating actions to manage distributed transactions. Keep operations small and idempotent.
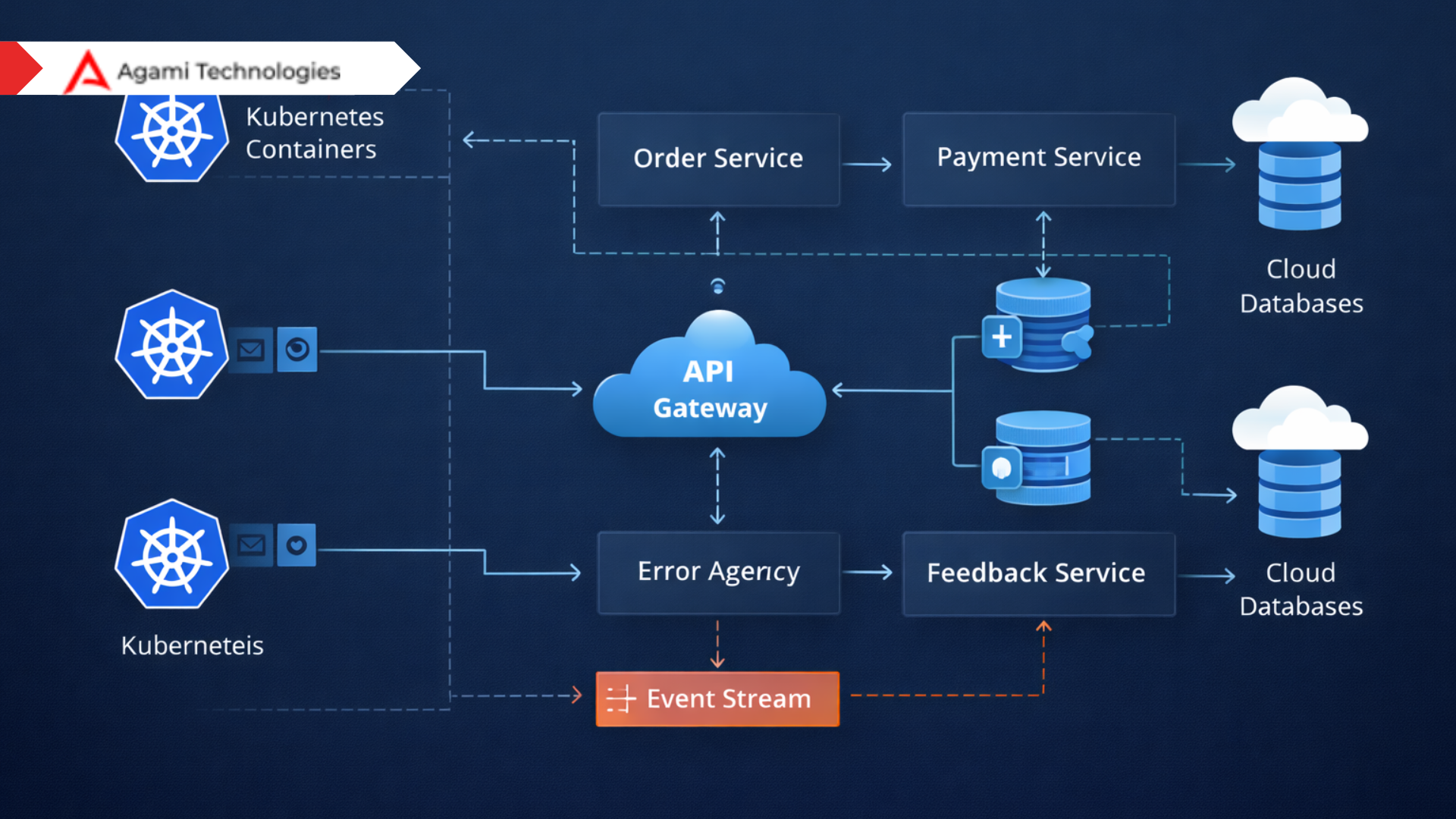
Example pattern. You have an order service and an inventory service. Instead of both writing to a shared database, the order service emits an event when an order is placed. The inventory service consumes the event and updates stock. If the inventory update fails, a compensating event corrects the order status. This keeps services autonomous and resilient.
Testing Strategies for Cloud Apps
Cloud environments make it easier to run realistic tests. But a testing strategy still matters. I recommend focusing on three levels.
- Unit tests for core logic.
- Integration tests against real or emulated services.
- End to end tests that exercise user journeys in a preview environment.
Use contract tests when services depend on each other. They let teams change implementation details while keeping interfaces stable. This reduces surprise breakages in production.
One simple example. If a payment service exposes an API, the consuming service should run a contract test against a mock that behaves like the payment API. That will catch breaking changes earlier.
Operational Readiness and Runbooks
When something fails, you want people to act fast. Runbooks and playbooks are simple tools that help. Document common failure modes, how to identify them, and how to roll back.
Make sure runbooks are accessible and updated. An outdated playbook can be worse than none because it gives a false sense of security. Run periodic drills that simulate incidents. The faster your team practices, the quicker they respond when it matters.
Scaling Teams and Building Leaders
Technical architecture and team structure are mirrors. If your architecture requires tight coordination, your org will also be tightly coupled. If your architecture supports autonomy, your teams can be more independent.
Early in my career, a boss told me, “I’m not thinking about this role. I’m thinking about you three roles from now.” He was not evaluating my performance. He was allocating future power. That changed how I think about building teams.
There are two leadership models I see.
- Capacity leadership. You centralize decisions and keep control. The team performs but needs you for everything.
- Compounding leadership. You expand decision rights before you feel comfortable. You let people own work that is a little above their current readiness. That builds judgment and depth.
Capacity leaders scale supervision. Compounding leaders scale leverage. The difference shows up when you are not in the room. Are decisions still getting made? Are people confident and accountable? If your team cannot outgrow you, you built extensions, not leaders.
Practical steps to build capability:
- Give engineers end to end ownership of a service.
- Delegate decision making with clear boundaries.
- Invest in onboarding and internal docs so people can onboard without depending on a single person.
- Coach and create stretch assignments that are safe to fail.
Working with a Cloud App Development Company
Partnering with the right cloud app development company can speed time to market and reduce risk. Look for partners who bring both technical skills and product thinking.
Here are things I recommend you check during evaluation:
- Do they have experience with cloud-native application development and SaaS application development?
- Can they show examples of AWS cloud application development or Azure cloud application development projects similar to yours?
- Do they follow DevOps cloud solutions and modern CI/CD practices?
- What is their approach to microservices architecture, security, and observability?
- How do they help transfer capability to your team so you’re not permanently dependent?
At Agami, we focus on custom cloud application development services that align with product and business outcomes. We help teams build scalable cloud applications, manage cloud migration services, and implement enterprise cloud solutions. We try to avoid short term fixes and focus on creating durable capability inside client organizations.
Roadmap: From Idea to Scalable Product
Here is a practical roadmap I use with early stage products. It balances speed with structural health.
- Discovery. Align on business goals, success metrics, and constraints. Identify the minimal viable architecture for those goals.
- Architectural choices. Choose a stack, determine data patterns, and map service boundaries. Build a prototype for risky parts.
- MVP build. Keep it simple. Use managed services to accelerate delivery. Ship core workflows and measure real usage.
- Platformization. Invest in CI/CD, observability, and test automation. Introduce feature flags and preview environments.
- Scale and optimize. Move to microservices where it helps, optimize costs, and build team capabilities.
A simple timeline for a small team could look like this. Weeks one and two for discovery and prototype. Weeks three through eight will be spent building the MVP. Start platform work in parallel once the MVP is stable. This keeps the product moving while you remove single points of failure. For more insights on architecture and engineering practices, explore the Agami Blog
Simple Examples You Can Try Today
Here are three small experiments you can run in a week to see cloud-native benefits quickly.
- Feature flag rollout. Add a feature flag to a new endpoint. Enable it for 10 percent of users, observe metrics, then roll it out. This reduces risk and supports fast learning.
- Preview environments for PRs. Auto-deploy every pull request to a separate preview URL. That makes manual testing fast and reduces integration surprises.
- Cost tagging and daily report. Tag resources for each product and send a daily cost email to the team. Small visibility drives big awareness and quick fixes.
Common Mistakes and How to Avoid Them
A few patterns repeat across teams. I have seen them enough times to call them out.
- Premature optimization. Don’t build complex distributed systems before you need them. Start simple and extract complexity when it slows you down.
- Ignoring runbooks. When emergencies happen, teams panic. Runbooks save time and reduce mistakes under pressure.
- Over centralization. If every change needs a committee, velocity collapses. Create small guardrails and let teams move.
- Underestimating data coupling. Sharing databases between services kills autonomy. Use APIs or events instead.
- Neglecting developer experience. If it is hard to ship, teams will take shortcuts that cause failures later.
How to Measure Success
Measure both product outcomes and platform health. A few useful metrics to track:
- Lead time for changes from commit to production.
- Change failure rate and mean time to recovery.
- Application latency and error rates for key user journeys.
- Infrastructure cost per active user or per transaction.
- Team health metrics such as cycle time for tickets and frequency of deployments.
These measures let you see whether architectural investments are paying off. For example, faster lead time and lower change failure rate indicate that your platform is enabling safe experimentation.
When to Consider Professional Help
There are times when bringing in a partner is the right move. Consider help when:
- Your team is blocked on cloud architecture and cannot deliver new features.
- You need to migrate critical workloads and cannot afford extended downtime.
- You want to accelerate a security or compliance initiative.
- You need to build a platform that scales multiple product teams.
A good partner will not just write code. They will transfer practices, help you avoid common mistakes, and leave your team stronger. That is the difference between a vendor and a partner.
Frequently Asked Questions.
Final Thoughts
Cloud application development is both about technology and about creating leverage inside your organization. You can buy cloud services, but you cannot buy judgment. That comes from deliberate practice, good leadership, and clear tradeoffs.
If you take anything from this post, let it be this. Start small, measure outcomes, and expand capability. Build systems that let your teams make decisions without waiting for sign off. That is how you scale real output and create a durable advantage.
Helpful Links and Next Steps
If you want a short, practical conversation about where to start, check out the links above. Book a meeting when you are ready to move from idea to production with less risk and more speed.